
The Quest for Thinking Machines
Humans are not immune from contradiction. Far from it. We sign treaties, yet we keep mass producing dangerous weapons.
We are taught about risk & peril from an early age, yet we choose to engage in helmet wearing eadeavours & jump out of airplanes.
Now clearly we're ready to dive into ASI.
We can barely manage misinformation & protect kids from social media...yet prospects of "thinking machines" are flooding the news.
From the IBM mainframe, to the rise of CRM software & algorithms like recommender systems, artificial intelligence has been steadily evolving & companies are racing to leverage their data analytics capabilities. AI is advertised everywhere. It's shadowing people's online actions (for behavior & business analytics) to say the least...clearly marking a new era of consumer' relationship with the digital world.
By the 1950's, computers were already known to the general public as post-ww2 investement in technology took off (in part influenced by the cold war) with projects being funded by both the government & public sectors. In order to distinguish a particular subfield topic involving both computers & robotics (known back then as "thinking machines"), John McCarthy - a Dartmouth mathematics professor took initiative in coining the term "Artificial Intelligence".
He contacted the Rockefeller foundation and requested funding to organize an event workshop on "Thinking Machines", where different scientists across many fields (like math, physics, psychology etc.) would be invited from all over the country to share their insights on the topic.
After srambling some funds for the project & inviting a few dozen scientists from across North America, with the support of a few dedicated colleagues (like Marvin Minsky) McCarthy managed to run the event which became known in history as the Dartmouth Summer Project of 1956.
The history of AI is complicated & desptite the complexity of the reasoning dynamics that many scientists poured decades of their lives into, i would like to discuss the major paradigm shifts that occurred over the years with this evolving technoloy, in order to clarify where we came from, and what potential future lies ahead of us.
In this article, i will discuss the evolution of AI in three separate parts:
- Symbolism
- The Statistics Era
- Deep Learning
Symbolism
In the early stages of AI development, scientists tried to lay the foundations with logic theory, manipulation of symbols & direct instruction based system rules.
The early suggested concepts heavily resembled the step-by-step solving method used my mathematicians, along the lines of Principia Mathematica, with an incentive to find more abstract & elegant proof variations.
Around the same period, system design reasoning concepts like "if-then-statements" were being experimented with, especially in biology, where certain methods showed success (even outperforming humans).
However, progress was only noticeable in very specific domains & constrained environments.
This approach showed scientists that heavily relying on symbolic AI involved a lot of human intervention, like encoding the system domain of a specific environment setting.
The reliance on human encoding was so critical, that if any particular rule was left out or was oversimplified for the logic, it would lead the system to crash.
This was in part, a data storage problem & a system design flaw that heavily relied on symbols directed at a tightly reserved domain.
For instance, a symbolic AI built for electrical design could not necessarily be applied in another field like chemistry or finance, without laborious human intervention & encoding.
Despite that, the conference group remained focused a lot on "symbolic logic" to finalize a theory on if this method might be a more flexible approach, than applying decision trees & complex arithmetics.
One scientist by the name of Trenchard More extended the notion of "symbolic logic", leading to a new concept called Array Theory.
The idea behind Array Theory suggested that granular input needed some kind of "order", and that data structures (arrays) would facilitate the system to interpret more complex information, alleviating stress on the resoning process.
MIT professor Marvin Minsky had insights on neural networks prior to the Dartmouth event, but was heavily influenced about symbolic logic by other colleagues from the conference.
Ray Solomonoff also had different insights and suggested a focus on probability reasoning. Despite Minsky taking notes of Solomonoff's ideas, he remained sidetracked on symbolic reasoning for the first few years after the conference, as most favored the consensus on a "symbolic approach" to AI.
The Era of Statistics
The second part of the AI framework evolution had a significant shift from the logic & deductive reasoning approach.
AI researchers realized that the reasoning process needed some kind of pattern recognition mechanism implemented, in order for the machine to analyze its own data feed.
Despite having limited compute power, inefficient hardware designs & lean math notions, emphasis was put on; correlation, distribution, and probability methods.
Three new tools were introduced:
- Decision Trees
- Baye's Theorem
- Support Vector Machines
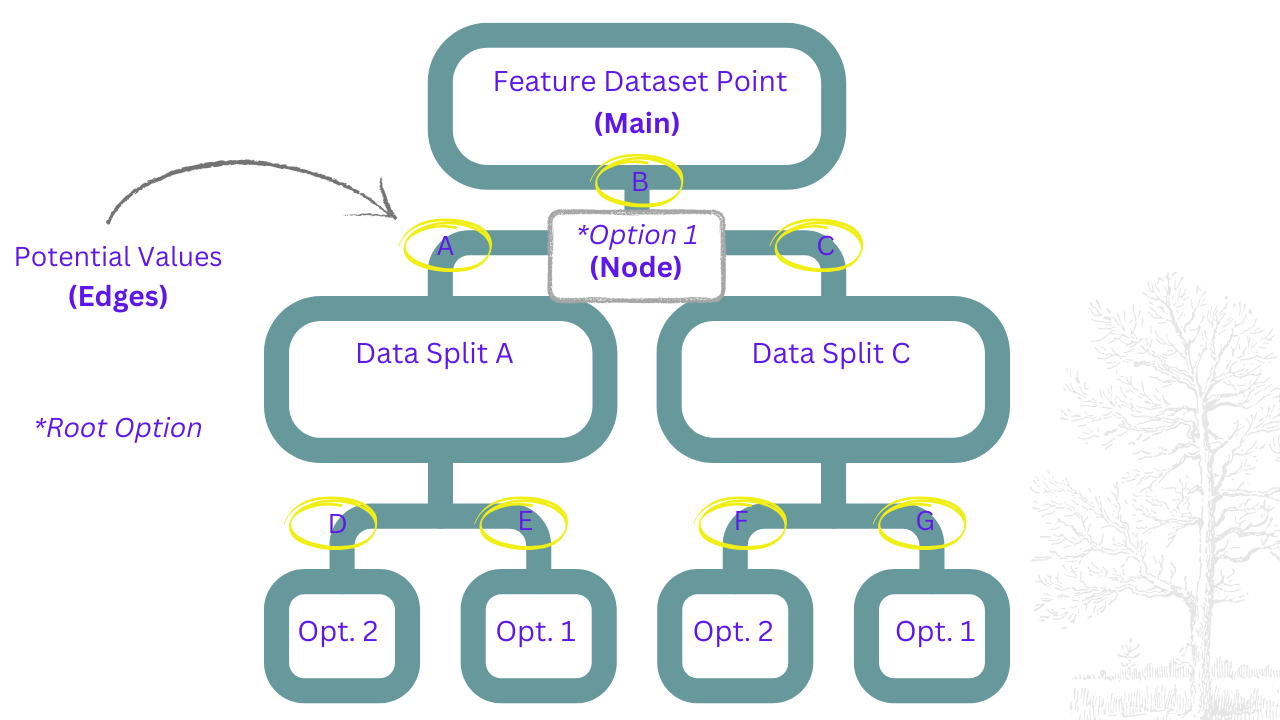
Decision trees started being implemented in the 1960's. This hierarchy based model allocates information & classifies data in a "tree-like" structure where each branch (arrow) represents a possible condition/value & each "leaf" or container/shape, a sub-classification
The bigger the tree, the more classifications it has as a result of the algorithm filtering the data for patterns/classes, using metrics like uncertainty & the Gini index (randomness/false input prediction).
Bayesian inference
With scaling challenges for Symbolic AI, as well as limitations like handling uncertainty, scientists started pivoting towards statistical approaches in order to accomodate the use of emerging real-world applications, like medical-diagnosis.
Bayesian inference is a mathematical premise based on Baye's Theorem, and it provided an initial approach for dealing with unstructured or incomplete data. This application (which includes a list of options of several probabilistic methods) is very suitable when new input (especially ambiguous data) is added (by comparing it to older information - using probability).
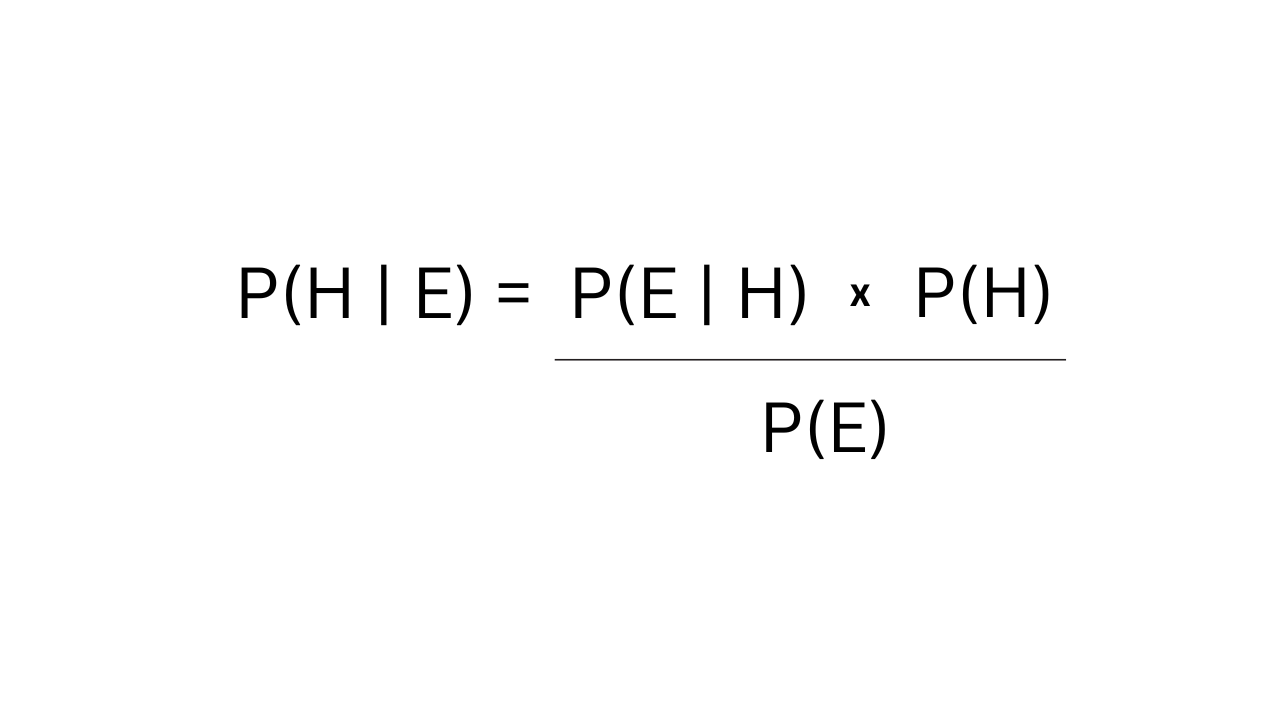
Baye's Theorem demonstrates the following;
- P(H|E):
With P for Probability, it presents the likelihood of the prediction (H), being accurate for the evidence (E).
- P(E|H):
What are the chances of witnessing the evidence (E) if the prediction (H) is accurate.
- P(H):
Initial estimate of prediction.
- P(E):
Description & general information (probabilities) of the evidence, despite any context/condition.
Support Vector Machines
In supervised learning, SVM's use a special mathematical technique that allows classifying data points into more dimensions
As digital data in society was rising, this method started being commonly used in the 1990's and made breakthroughs in fields like image-classification & bioinformatics
There are two types of SVM's - categorized as: linear classifier & non-linear classifier.
Support Vector Machines were the high point of the era of statistics - this method was now able to interpret complex patterns of data (where linear models would normally fail), be more resilient to overfitting (its designed with a balancing parameter called "regularization") & efficiently benefit its generalization improvement.
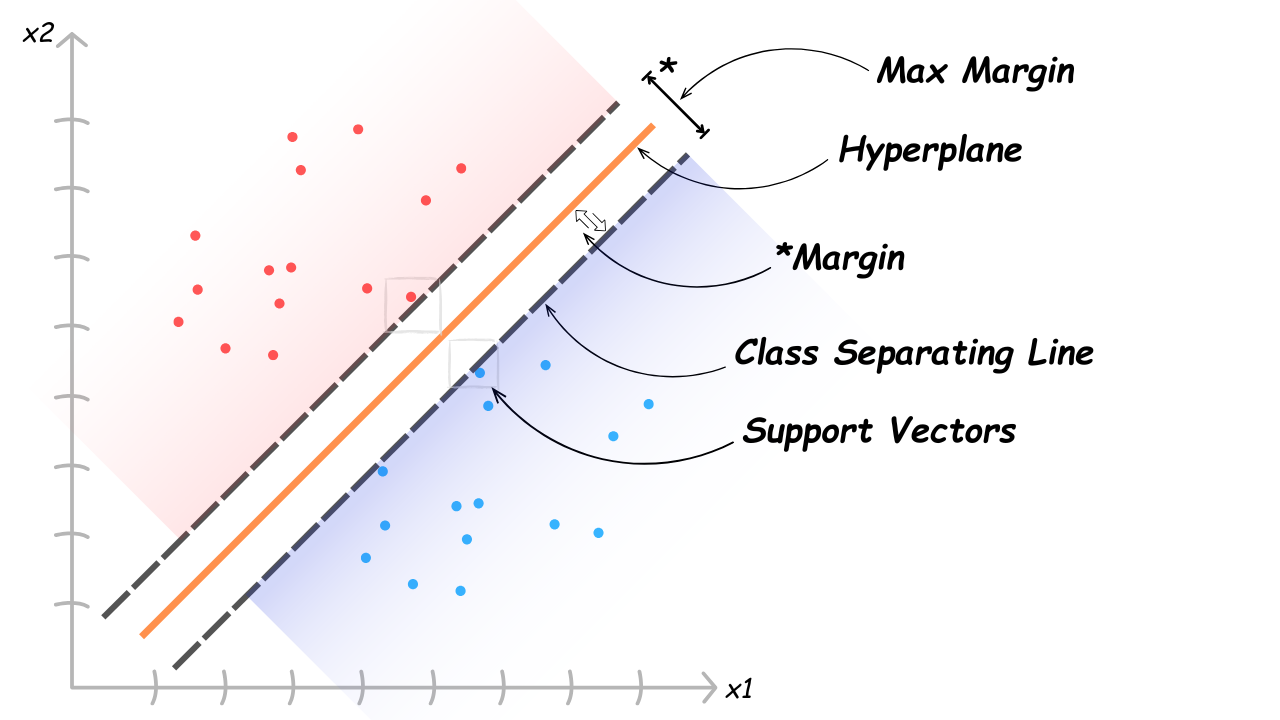
The method basically works by identifying the ideal hyperplane. In the example above, the "hyperplane" is just a line (as this is a 2-d example). The higher the dimension (3d etc.) the more abstract the hyperplane assembly is.
The closest data points (support vectors) to the class separator (or decision boundary) are selected using a mapping technique called kernel function. The bigger the margin identified by the model - the more it influences the generalization (the more confidence the model has in the inclusive data points). The regularization parameter then acts as the balancer for overfitting, depending on whether the outcome is intended for simplicity, or tightness to the training data.
Deep Learning
In the 1980's, significant advances in network processing were made by attempting to model the neural structure of the human brain (like convolutional neural networks - inspired by the visual cortex).
Newer fundamental math frameworks (like gradient descent & backpropagation) were introduced, which act like "engines" for orchestrating the billions of parameters. Because data structure concepts were in their early stages..,image processing was progressing faster than language processing. Notions of CNNs were adopted promptly: like convolutional layers (image pattern recognition), pooling layers (optimizing robustness while retaining critical data) & weight sharing (limiting overfitting).
Recurrent Neural Networks (RNNs) were being developed for language processsing, however their math factors were limiting at the time (until the logic/information flow improved in the late 1990's).
Below is a simplified explanation of gradient descent & backpropagation:
Gradient descent uses an optimization calculation, and there are different variants of that technique (e.g. stochastic variant approach). It's goal is to reduce the loss function ("gradients" being the vectors of partial derivatives), by repetitively adjusting its weights/biases (course correction).
While gradient descent works as an "adjuster" of parameters, backpropagation is the one that actually does the computation (of the loss function) & sends the signal from the output layer for the weights update.
As a fundamental function of deep learning, backpropagation is used across many industries & applications. Below is a simple visual representation, showcasing how banks might apply the backpropagation concept for fraud detection.
RNNs got better with the Long-Short-Term-Memory (LSTM) technique and gradually, with large datasets, GPU's (Graphics Processing Units), better algorithms & optimized training, neural networks started attracting more academics & researchers again. In 2012 a team at the University of Toronto came up with a breakthrough architecture called "Alexnet" and introduced it to the ImageNet database, which set a new benchmark record in the annual computer vision challenge.

New methodologies like embedding got developed, and gave the power to leverage vector representations - which vastly improved applications in language modeling, translation & speech recognition.

Pretraining opened the door for more deep level data extraction, reducing the trouble of only using labeled datasets.
Transfer learning also changed the AI landscape, as it allowed cross-training models to direct them for different tasks.
These later stages of AI development allowed researchers to learn how to fine-tune their models & focus more on developing applications,..leading to newer modern paradigms in machine learning.